
PL/SQLで正規表現を使って文字列抽出する事になったので以下検証結果を残します。正規表現って、書き上げた当時はきちんと理解しているつもりですが、数日もするとすぐに忘れちゃうんですよね。
まずは「お題」となるSQL
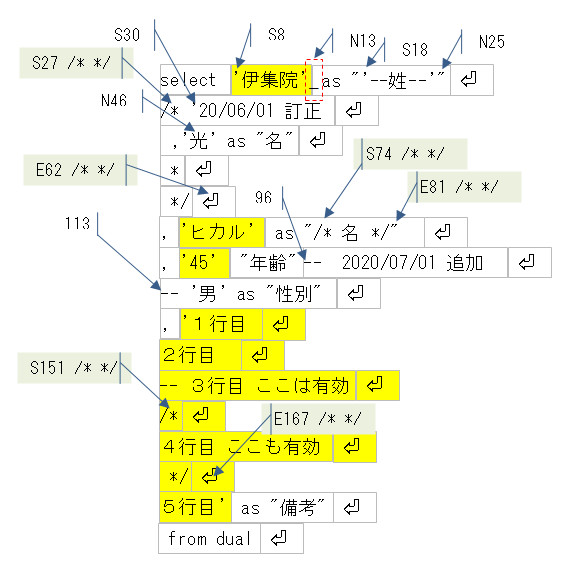
以下ちょっと意地悪なSQLを実行して、V$SQLのSQL_FULLTEXTに入れます。
select '伊集院' as "'--姓--'" /* '20/06/01 訂正 ,'光' as "名" * */ ,'ヒカル' as "/* 名 */" ,'45' "年齢" -- 2020/07/01 追加 -- '男' as "性別" ,'1行目 2行目 -- 3行目 ここは有効 /* 4行目 ここも有効 */ 5行目' as "備考" from dual ;
実行結果はこの通りで、V$SQLを調べるとSQL_IDは「71xa1sxnvdc92」である事わかりました。
SQL> set lin 200
SQL> COLUMN 備考 FORMAT A50
SQL> select '伊集院' as "'--姓--'"
2 /* '20/06/01 訂正
3 ,'光' as "名"
4 *
5 */
6 ,'ヒカル' as "/* 名 */"
7 ,'45' "年齢" -- 2020/07/01 追加
8 -- '男' as "性別"
9 ,'1行目
10 2行目
11 -- 3行目 ここは有効
12 /*
13 4行目 ここも有効
14 */
15 5行目' as "備考"
16 from dual
17 ;
'--姓--' /* 名 */ 年齢 備考
------------------ ------------------ ---- --------------------------------------------------
伊集院 ヒカル 45 1行目
2行目
-- 3行目 ここは有効
/*
4行目 ここも有効
*/
5行目
SQL> select prev_sql_id from v$session where sid = sys_context('USERENV','SID')
2 ;
PREV_SQL_ID
--------------------------
71xa1sxnvdc92
SQL>
/* */で囲まれた部分抽出
先頭から3つ目の/* */で囲まれた部分の抽出
select REGEXP_INSTR(t.SQL_FULLTEXT,'/\*(*[^\*]/.|[^/]|\*[^\*])+*/',1,3,1,'n') offset_no from v$sql t where t.SQL_ID = '71xa1sxnvdc92' ; select REGEXP_SUBSTR(t.SQL_FULLTEXT,'/\*(*[^\*]/.|[^/]|\*[^\*])+*/',1,3) as outword from v$sql t where t.SQL_ID = '71xa1sxnvdc92' ;
SQL> select REGEXP_INSTR (t.SQL_FULLTEXT,'/\*(*[^\*]/.|[^/]|\*[^\*])+*/',1,3,1,'n') offset_no from v$sql t where t.SQL_ID = '71xa1sxnvdc92'
2 ;
OFFSET_NO
----------
166
SQL> select REGEXP_SUBSTR(t.SQL_FULLTEXT,'/\*(*[^\*]/.|[^/]|\*[^\*])+*/',1,3) as outword from v$sql t where t.SQL_ID = '71xa1sxnvdc92'
2 ;
OUTWORD
--------------------------------------------------------------------------------
/*
4行目 ここも有効
*/
SQL>シングルクォーテーションで囲まれた部分抽出
先頭から6つ目のシングルクォーテーションで囲まれた部分の抽出
select REGEXP_INSTR (t.SQL_FULLTEXT,'''[^*\'']*''',1,6,0,'c') offset_no from v$sql t where t.SQL_ID = '71xa1sxnvdc92' ; select REGEXP_SUBSTR(t.SQL_FULLTEXT,'''[^*\'']*''',1,6,'c') as outword from v$sql t where t.SQL_ID = '71xa1sxnvdc92' ;
SQL> select REGEXP_INSTR (t.SQL_FULLTEXT,'''[^*\'']*''',1,6,0,'c') offset_no from v$sql t where t.SQL_ID = '71xa1sxnvdc92'
2 ;
OFFSET_NO
----------
115
SQL> select REGEXP_SUBSTR(t.SQL_FULLTEXT,'''[^*\'']*''',1,6,'c') as outword from v$sql t where t.SQL_ID = '71xa1sxnvdc92'
2 ;
OUTWORD
--------------------------------------------------------------------------------
'男'
SQL>ダブルクォーテーションで囲まれた部分抽出
先頭から4つ目のダブルクォーテーションで囲まれた部分の抽出
select REGEXP_INSTR (t.SQL_FULLTEXT,'\"[^\"]*\"',1,4,0,'c') offset_no from v$sql t where t.SQL_ID = '71xa1sxnvdc92' ; select REGEXP_SUBSTR(t.SQL_FULLTEXT,'\"[^\"]*\"',1,4,'c') as outword from v$sql t where t.SQL_ID = '71xa1sxnvdc92' ;
SQL> select REGEXP_INSTR (t.SQL_FULLTEXT,'\"[^\"]*\"',1,4,0,'c') offset_no from v$sql t where t.SQL_ID = '71xa1sxnvdc92'
2 ;
OFFSET_NO
----------
89
SQL> select REGEXP_SUBSTR(t.SQL_FULLTEXT,'\"[^\"]*\"',1,4,'c') as outword from v$sql t where t.SQL_ID = '71xa1sxnvdc92'
2 ;
OUTWORD
--------------------------------------------------------------------------------
"年齢"
「–」と「改行」 で囲まれた部分抽出
select REGEXP_INSTR (t.SQL_FULLTEXT,'--.*',1,1,0) offset_no from v$sql t where t.SQL_ID = '71xa1sxnvdc92' ; select REGEXP_SUBSTR(t.SQL_FULLTEXT,'--.*',1,1) as outword from v$sql t where t.SQL_ID = '71xa1sxnvdc92' ; select REGEXP_SUBSTR(t.SQL_FULLTEXT,'--.*',1,2) as outword from v$sql t where t.SQL_ID = '71xa1sxnvdc92' ; select REGEXP_SUBSTR(t.SQL_FULLTEXT,'--.*',1,3) as outword from v$sql t where t.SQL_ID = '71xa1sxnvdc92' ;
さらに追加
「ある文字」で始まる文字列を抽出する。
-- 'scott.costomer' のcostomer部分だけを切り出す。
-- まず「.」以降の文字列を抽出し、substrで「.」を外すというやり方。
select substr(REGEXP_SUBSTR('scott.costomer','\.[a-zA-Z0-9._$]+',1,1,'i'),2) from dual
;
「ある文字」で囲まれた部分を抽出する。
-- sample1
-- ()で囲まれた部分の抽出。間に改行が入った場合も対象として抽出する。
-- '\(([^*]|\*[^/])*\)'
--
SQL> select REGEXP_SUBSTR('select * from ( ex01 ) ','\(([^*]|\*[^/])*\)',1,1) as outword from dual;
OUTWORD
---------------------------
( ex01 )
空行を削除する。
-- まずは2つ以上続く改行を1つの改行にする
SQL> select regexp_replace(CHR(10)||'[a1]'||CHR(10)||'[b2]'||CHR(10)||CHR(10)||CHR(10)||'[c3]', '[[:cntrl:]]{2,}',CHR(10),1) after from dual;
AFTER
---------------------------------------------
[a1]
[b2]
[c3]
-- 先頭改行始まり(1つだけ)の場合は不要なので削除
SQL> select regexp_replace(CHR(10)||'[a1]'||CHR(10)||'[b2]'||CHR(10)||'[c3]', '^[[:cntrl:]]','',1) after from dual;
AFTER
------------------------------------------
[a1]
[b2]
[c3]
SQL>
-- まとめてやるなら
SQL> select regexp_replace(
regexp_replace(CHR(10)||'[a1]'||CHR(10)||'[b2]'||CHR(10)||CHR(10)||CHR(10)||'[c3]'
, '[[:cntrl:]]{2,}',CHR(10),1)
, '^[[:cntrl:]]','',1) after from dual
;
AFTER
----------
[a1]
[b2]
[c3]
