
Unicodeの中でもUTF-8は他の符号化方式(UTF-16、UTF32)と比べ可変長である点においては特殊です。文字によって1byte~4byteに長さが異なります。裏を返すとコードポイントの範囲によって「何バイト使用するのか」が決まります。このルールは固定長と比較して複雑ではありますがASCII文字と重複する部分は同じ1バイトで表現している点は大きなメリットだと思います。また、WEBサイトの文字コードシェアを見ても圧倒的にUTF-8が利用されています。
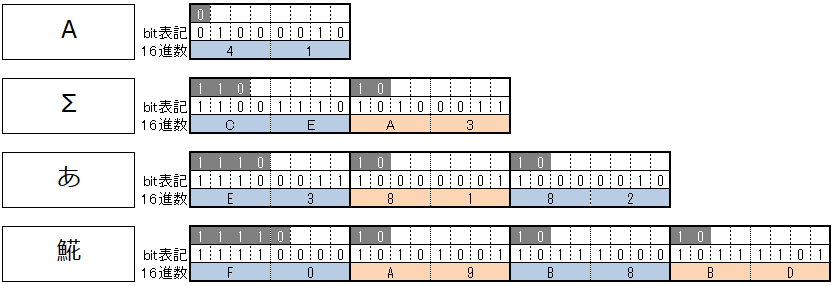
1~4バイト構成文字例
| バイト | 割当の範囲 | 例 | |||
| 文字 | コードポイント | 16進数 | 補足 | ||
| 1バイト文字 | U+0000〜U+007F | A | U+0041 | 0x41 | 半角大文字”A” |
| 2バイト文字 | U+0080〜U+07FF | Σ | U+03A3 | 0xCEA3 | シグマ(U+2211にも∑が割り当たっているがこれとは別物。U+2211のシグマは3バイト文字) |
| 3バイト文字 | U+0800〜U+FFFF | あ | U+3042 | 0xE38182 | 通常の「あ」 |
| 4バイト文字 | U+10000〜U+10FFFF | ? | U+29E3D | 0xF0A9B8BD |
ホッケ(魚+花) |
文字境界の判定方法
下図のように、UTF-8 では「先頭バイトの上位ビット」がその文字が何バイトで構成されるかを決定します。続くバイトは必ず 10xxxxxx という形式になるため、文字境界を誤認しないように設計されています。つまり、先頭バイトは絶対に 10 で始まらず、後続バイトは必ず 10 で始まるという法則が成り立ちます。(自己同期性と呼ぶらしい)この法則のおかげで、データの途中から読み始めても文字の境界を正しく復元でき、文字化けを回避できます。
一方、Shift_JIS にはこのような判別ルールが存在しないため、途中データからでは「先頭か後続か」を判断できません。そのため、ネットワーク転送中の欠損などが起きた場合、正しく復元することができません。

